


Table of contents
- Introduction to Big Data and Hadoop:
- Note:
- Overview:
- Traditional Decision-Making Process:
- Challenges of Traditional Decision-Making Process:
- Big Data Analytics - Solution for Challenges in Traditional Decision-Making Process:
- Case Study: Google’s Self-Driving Car:
- Big Data:
- Five V’s of Big Data:
- Big Data Analytics Pipeline:
- Types of Data:
- Distributed System:
- Hadoop:
- Hadoop Single Node Installation:
Introduction to Big Data and Hadoop:
Note:
These are just study materials I made for myself for career development when I was learning BigData.
Overview:
Understand the concepts of Big Data.
Explain Hadoop and how it addresses Big Data challenges.
Describe the components of the Hadoop ecosystem.
Traditional Decision-Making Process:
Based on the perception of the task at hand.
Experience and intuition also played a major role in the traditional decision-making process.
Decisions are made based on past experiences and personal instincts.
Decisions are made based on preconceived guidelines rather than facts.
Challenges of Traditional Decision-Making Process:
Takes a long time to arrive at a decision, therefore losing the competitive advantage.
Required human intervention at various stages.
Lacks systematic linkage among strategy, planning, execution, and reporting.
Provides limited scope of data analytics, that is, it provides only a bird’s eye view.
Obstructs the company’s ability to make a fully informed decision.
Big Data Analytics - Solution for Challenges in Traditional Decision-Making Process:
The decision-making is based on data and facts derived from data using data analytics.
It provides a comprehensive view of the overall picture which is a result of analyzing data from various sources.
It provides streamlined decision-making from top to bottom.
Big data analytics helps in analyzing unstructured data.
It helps in faster decision-making thus improving the competitive advantage and saving time and energy.
Case Study: Google’s Self-Driving Car:
Technical Data (Inside Out) →Learning about avoiding obstacles like cones, cyclists, etc... It's the data that comes from the sensors in the car.
Community Data (Outside In) → Crowd-sourced data like traffic, driving conditions, etc...
Personal Data → Drivers' personal preferences regarding driving locations, in-car entertainment, etc...
Big Data:
Data that contains greater variety, arriving in increasing volumes and with more velocity.
Put simply, Big Data is larger, more complex data sets, especially from new data sources. These data sets are so voluminous that traditional data processing software just can’t manage them.
But these data sets can be used to address business problems that couldn’t be tackled before.
Five V’s of Big Data:
Volume:
In Big Data, high volumes of low-density, unstructured data should have to be processed.
This can be data of unknown value, such as Twitter data feeds, clickstreams on a web page or a mobile app.
These can be tens of terabytes of data. In some other cases, these can be hundreds of petabytes.
Value:
- Value of Big Data usually comes from insight discovery and pattern recognition that lead to more effective operations, stronger customer relationships and other clear and quantifiable business benefits.
Variety:
Variety refers to many types of data that are available.
In Big Data, data comes in new unstructured data types.
Unstructured and semi-structured data types, such as text, audio, and video, require additional processing to derive meaning and support metadata.
Velocity:
The fast rate at which data is received and acted on.
Normally, the highest velocity of data streams is directed into memory versus being written to disk.
Veracity:
- The truth or accuracy of data and information assets often determines executive-level confidence.
Big Data Analytics Pipeline:
Data Ingestion Layer
The first step is to ingest or catch the data coming from variable sources.
Data here is prioritized and categorized which makes data flow easier in the further layers.
Data Collector Layer:
The focus is on the transportation of data from the ingestion layer to the rest of the data pipeline.
In this layer, components are decoupled, so that analytic capabilities may begin.
Data Processing Layer:
The focus is to build the data pipeline processing system.
Route the data to a different destination, and classify the data flow, and it's the first point where analytics may take place.
Data Storage Layer:
- Focuses on where to store a large dataset efficiently.
Data Query Layer:
Active analytical processing takes place.
The focus is to gather the data's value so that it is made more helpful for the next layer.
Data Visualization Layer:
- Focuses on visualizing the processed data to make it more understandable.
Types of Data:
Structured Data:
- Data that has a defined data model format and structure such as Database.
Semi-Structured Data:
- Textural data files with an apparent pattern, enabling analysis such as Spreadsheets, JSON and XML files.
Quasi-Structured Data:
- Textual data with erratic formats such as click-stream data can be formatted with effort and software tools.
Unstructured Data:
- Data that has no inherent structure and is usually stored as different types of files such as PDFs, images, weblogs, etc...
Distributed System:
It is a model in which components located on networked computers communicate and coordinate their actions by passing messages.
It helps to process big data in a massively parallel way in much less time.
Hadoop:
Hadoop is a framework that allows distributed processing of large datasets across clusters of commodity computers using simple programming models.
Characteristics of Hadoop:
Economical → Can use ordinary computers for data processing.
Reliable → Stores copies of data on different machines and is resistant to hardware failure.
Scalable → Can scale both horizontally and vertically.
Flexible → Can store huge amounts of data (both structured and unstructured) and decide to use it later.
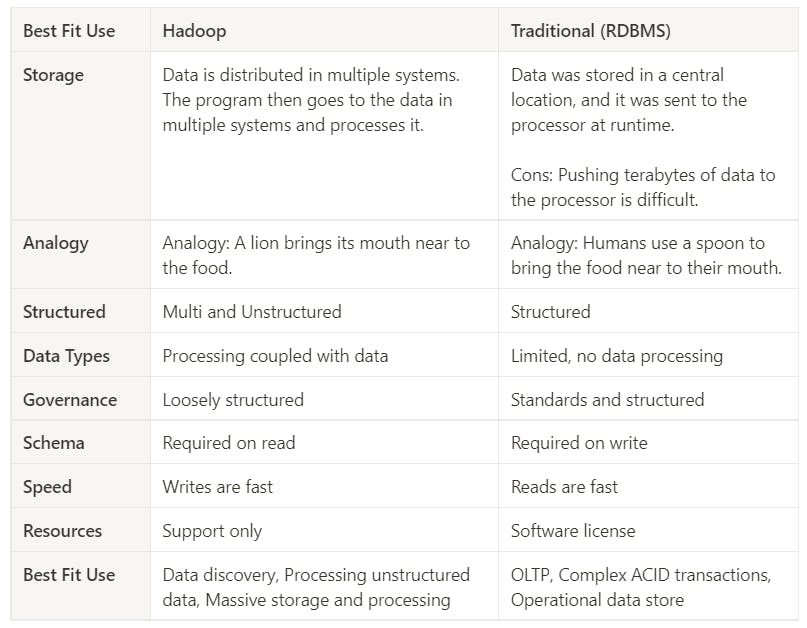
Difference: Traditional Storage Systems Vs Hadoop:
Hadoop Core Components:
The below components are closely coupled.

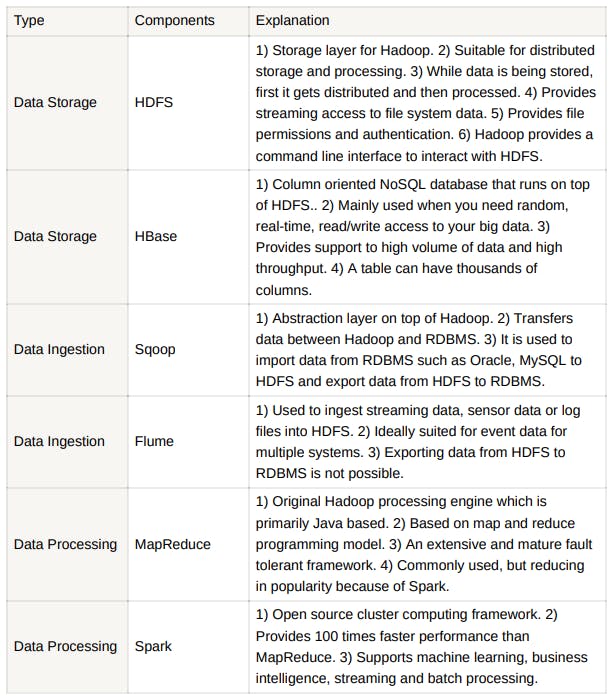
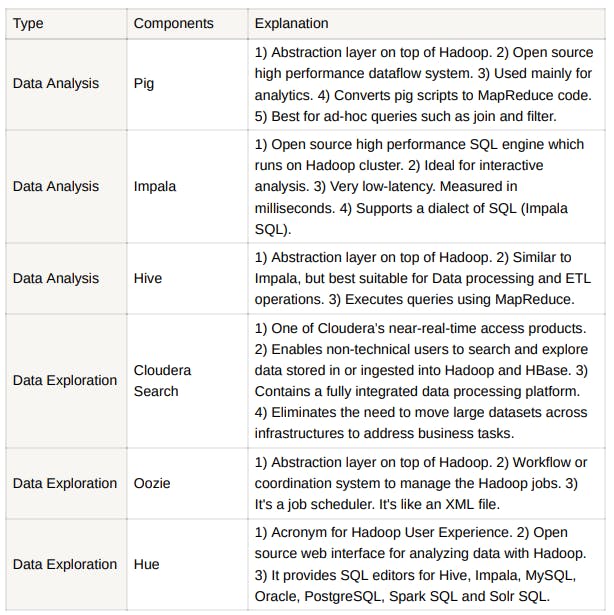
Components of BigData in-terms of Hadoop and Data Visualization:

Explanation of the Hadoop Ecosystem Components:
Hive, Pig, Scoop and Oozie all need Map Reduce engine to work. So, these are called Abstraction of Map Reduce. If the Map Reduce process is killed, all these processes will also stop working.
Five Daemons of Hadoop and Configuration Files:
Namenode → core-site.xml
Datanode → Workers
Node manager → Workers and yarn-site.xml
Resource Manager → mapped-site.xml
Secondary name node
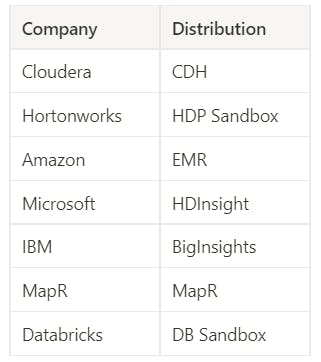
Commercial Hadoop Distributions:
Apache Hadoop doesn’t give any support if anything goes wrong from using its distribution of Hadoop. So, many companies provide Hadoop as a service and give support for commercial purposes.
Hadoop Single Node Installation:
Download Java 8 from Oracle and Hadoop from the Apache Hadoop website. [Note: Download tar.gz files]
Extract the two and place them in the home directory.
Open the .bashrc file and add the below environment variables.
export JAVA_HOME=/home/<your_username>/Hadoop/jdk1.8.0_311 export HADOOP_HOME=/home/<your_username>/Hadoop/hadoop-3.3.1 export PATH=$JAVA_HOME/bin:$HADOOP_HOME/bin:$PATH --> This line should always be at the lastModify the configuration files below (Add these snippets between configuration tags):
etc/hadoop/core-site.xml<property> <name>fs.default.name</name> <value>hdfs://localhost:50000</value> </property>etc/hadoop/yarn-site.xml<property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name> <value>org.apache.hadoop.mapred.ShuffleHandler</value> </property> <property> <description>The hostname of the RM.</description> <name>yarn.resourcemanager.hostname</name> <value>localhost</value> </property> <property> <description>The address of the applications manager interface in the RM.</description> <name>yarn.resourcemanager.address</name> <value>localhost:8032</value> </property>etc/hadoop/hdfs-site.xml<property> <name>dfs.namenode.name.dir</name> <value>/home/your_username/Hadoop/hadoop2-dir/namenode-dir</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>/home/your_username/Hadoop/hadoop2-dir/datanode-dir</value> </property>etc/hadoop/mapred-site.xml<property> <name>mapreduce.framework.name</name> <value>yarn</value> </property>etc/hadoop/workerslocalhostetc/hadoop/hadoop-env.shexport JAVA_HOME=/home/<your_username>/Hadoop/jdk1.8.0_311etc/hadoop/mapred-env.shexport JAVA_HOME=/home/<your_username>/Hadoop/jdk1.8.0_311etc/hadoop/yarn-env.shexport JAVA_HOME=/home/<your_username>/Hadoop/jdk1.8.0_311
Install SSH and configure it to ask for no password: [Note: Never install pdsh]
sudo apt-get install openssh-server ssh-keygen -t rsa cd .ssh cat id_rsa.pub >> authorized_keysTest SSH by logging into localhost:
ssh localhostFormat Namenode: [After formatting, namenode-dir will be created]
cd ~/Hadoop/hadoop-3.3.1 bin/hadoop namenode -formatStart the services: [All five daemons will start. datanode-dir will be created]
cd ~/Hadoop/hadoop-3.3.1/sbin ./start-all.shCheck if all the services are running:
jpsCheck the browser Web UI:
Namenode → http://localhost:9870/
Resource Manager → http://localhost:8088/
Stop the services: [All the five daemons will stop]
cd ~/Hadoop/hadoop-3.3.1/sbin ./stop-all.sh